Spring Data R2DBC enables us to write non-blocking code for interacting with databases. Unlike the other Spring Data projects, Spring Data R2DBC isn't an ORM and has some limitations. One of those limitations is mapping joins for entities. This presents a challenge for those familiar with Spring Data JPA. How do you write non-blocking code, while also joining and mapping complex entities?
Let's find out.
The full code for this post can be found on Github. This post is only a small part of this repository.
Table of Contents:
Spring Data R2DBC
Like other Spring Data projects, the goal of Spring Data R2DBC is to make working with databases easy. To achieve this in a reactive way, they had to drop many features. Spring Data R2DBC is not an ORM framework and does not support joins.
For a simple entity, with no relationships, R2DBC works great. Make an entity class and supporting repository.
When it comes to entities with relationships, this pattern no longer works. To overcome this, we need to create our own repository implementation using DatabaseClient.
So let's get started.
The Entities
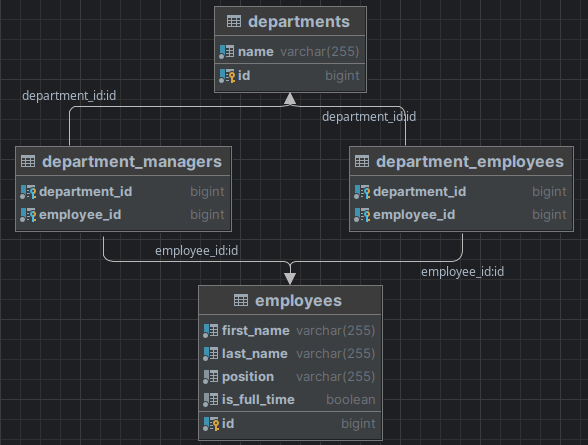
We will use two entities, a basic Employee, and a Department that has two different relationships with Employee.
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Table("employees")
public class Employee {
@Id
private Long id;
private String firstName;
private String lastName;
private String position;
@Column("is_full_time")
private boolean fullTime;
public static Employee fromRow(Map<String, Object> row) {
if (row.get("e_id") != null) {
return Employee.builder()
.id((Long.parseLong(row.get("e_id").toString())))
.firstName((String) row.get("e_firstName"))
.lastName((String) row.get("e_lastName"))
.position((String) row.get("e_position"))
.fullTime((Boolean) row.get("e_isFullTime"))
.build();
} else {
return null;
}
}
public static Employee managerFromRow(Map<String, Object> row) {
if (row.get("m_id") != null) {
return Employee.builder()
.id((Long.parseLong(row.get("m_id").toString())))
.firstName((String) row.get("m_firstName"))
.lastName((String) row.get("m_lastName"))
.position((String) row.get("m_position"))
.fullTime((Boolean) row.get("m_isFullTime"))
.build();
} else {
return null;
}
}
}@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Table("departments")
public class Department {
@Id
private Long id;
private String name;
private Employee manager;
@Builder.Default
private List<Employee> employees = new ArrayList<>();
public Optional<Employee> getManager(){
return Optional.ofNullable(this.manager);
}
public static Mono<Department> fromRows(List<Map<String, Object>> rows) {
return Mono.just(Department.builder()
.id((Long.parseLong(rows.get(0).get("d_id").toString())))
.name((String) rows.get(0).get("d_name"))
.manager(Employee.managerFromRow(rows.get(0)))
.employees(rows.stream()
.map(Employee::fromRow)
.filter(Objects::nonNull)
.toList())
.build());
}
}You will notice that these entities have static methods to create objects from an input. These are the raw results from a call using DatabaseClient. Since Spring Data R2DBC won't map these objects, we have write the logic ourselves. row.get is our best friend here, allowing us to extract any column and cast it to the type that we need.
The Repository
Earlier I said that standard repositories are fine for entities without relationships. Meaning all we need to do for Employee is create our annotated interface.
@Repository
public interface EmployeeRepository extends R2dbcRepository<Employee, Long> {
Flux<Employee> findAllByPosition(String position);
Flux<Employee> findAllByFullTime(boolean isFullTime);
Flux<Employee> findAllByPositionAndFullTime(String position, boolean isFullTime);
Mono<Employee> findByFirstName(String firstName);
}To keep the same pattern for Department, we need an interface and implementation class, DepartmentRepository and DepartmentRepositoryImpl.
@Component
public interface DepartmentRepository {
Flux<Department> findAll();
Mono<Department> findById(long id);
Mono<Department> findByName(String name);
Mono<Department> save(Department department);
Mono<Void> delete(Department department);
}@Component
@RequiredArgsConstructor
public class DepartmentRepositoryImpl implements DepartmentRepository {
private final EmployeeRepository employeeRepository;
private final DatabaseClient client;
// ... implementation
}I won't be going into all of the code for this repository, so you can check out the repo for full details.FindAll and FindById
As we are going to writing our own queries, we should start with a constant that describes our object.
private static final String SELECT_QUERY = """
SELECT d.id d_id, d.name d_name, m.id m_id, m.first_name m_firstName, m.last_name m_lastName,
m.position m_position, m.is_full_time m_isFullTime, e.id e_id, e.first_name e_firstName,
e.last_name e_lastName, e.position e_position, e.is_full_time e_isFullTime
FROM departments d
LEFT JOIN department_managers dm ON dm.department_id = d.id
LEFT JOIN employees m ON m.id = dm.employee_id
LEFT JOIN department_employees de ON de.department_id = d.id
LEFT JOIN employees e ON e.id = de.employee_id
""";We give each column an alias to use when extracting data to make our objects, as seen in the entity classes above. It is not necessary to use aliases, but it can be handy if a column name does not match the field name.
With our SELECT query ready to go, when can write our findAll() method.
@Override
public Flux<Department> findAll() {
return client.sql(SELECT_QUERY)
.fetch()
.all()
.bufferUntilChanged(result -> result.get("d_id"))
.flatMap(Department::fromRows);
}Let's breakdown what this is doing. First we have client.sql(SELECT_QUERY).fetch().all(), which fetches all of the data we asked for in our query. Since we are joining tables, we will have multiple rows for each Department. .bufferUntilChanged(result -> result.get("d_id")) collects all of the same rows together into a List<Map<String, Object>, before finally passing that to our last line which extracts the data and returns our Department objects.
To recap:
.client.sql(SELECT_QUERY).fetch().all()- Grab all of the data we asked for
.bufferUntilChanged(result -> result.get("d_id"))- Group the rows into a list based on department.id
.flatMap(Department::fromRows)- Turn each result set into a
Department
- Turn each result set into a
Simple, right? findById() is similar, with a minor tweak.
@Override
public Mono<Department> findById(long id) {
return client.sql(String.format("%s WHERE d.id = :id", SELECT_QUERY))
.bind("id", id)
.fetch()
.all()
.bufferUntilChanged(result -> result.get("d_id"))
.flatMap(Department::fromRows)
.singleOrEmpty();
}Here we are adding a where clause, bind the id and fetch all the rows as we did before. A new method at the end ensures we only return a single result or Mono.empty(). Using this method as a template, you can create any findBy* methods you might need.
Persisting Entities
Retrieving an entity is straightforward, ask for some data, build an object from it. But what if we want to persist data? We must persist the Department, manager Employee, and a list of Employee's. I will not be sharing all the code for this, as it is quite long, but I will walk through the idea of how it works.
The full code for this can be here.
The easiest way to understand persisting these entities is using a 'pipeline' of steps. For our example entities, it would look like this:
- Save or update the
Department - Save or update the manager
Employee - Save or update each employee
- Update the relationship between
DepartmentandManager - Update the relationship between
DepartmentandEmployee's
The public method looks exactly like the list above:
@Override
@Transactional
public Mono<Department> save(Department department) {
return this.saveDepartment(department)
.flatMap(this::saveManager)
.flatMap(this::saveEmployees)
.flatMap(this::deleteDepartmentManager)
.flatMap(this::saveDepartmentManager)
.flatMap(this::deleteDepartmentEmployees)
.flatMap(this::saveDepartmentEmployees);
}We pass the initial Department through each step, modifying state as we go.
While working on this project and learning about reactive streams, this method was the one to make the whole thing click for me.
Below is the first step in this pipeline, saveDepartment.
Mono<Department> saveDepartment(Department department) {
if (department.getId() == null) {
return client.sql("INSERT INTO departments(name) VALUES(:name)")
.bind("name", department.getName())
.filter((statement, executeFunction) -> statement.returnGeneratedValues("id").execute())
.fetch().first()
.doOnNext(result -> department.setId(Long.parseLong(result.get("id").toString())))
.thenReturn(department);
} else {
return this.client.sql("UPDATE departments SET name = :name WHERE id = :id")
.bind("name", department.getName())
.bind("id", department.getId())
.fetch().first()
.thenReturn(department);
}
}We see that there are two branches, one for persisting a new entity, and one for updating it. In the first, we use our client to insert a new Department, returning an id. We then set the id of our Department object before returning it for the next step. Each step after will do the same, persist an entity and set it back to our main entity.
After the Department has been persisted, we can move on to the other nested entities. Each nested entity requires threes steps, which you will see below for the department manager.
First we persist the manager. Using the EmployeeRepository makes this easy, as we don't have to decide between an insert or update like we do with Department. Once persisted, we set the Department's manager object to the new/updated Employee.
Mono<Department> saveManager(Department department) {
return Mono.justOrEmpty(department.getManager())
.flatMap(employeeRepository::save)
.doOnNext(department::setManager)
.thenReturn(department);
}After the entity has been persisted, we want to persist the relationship between Department and Employee. First we must delete any existing relationship.
private Mono<Department> deleteDepartmentManager(Department department) {
String query = "DELETE FROM department_managers WHERE department_id = :departmentId OR employee_id = :managerId";
return Mono.just(department)
.flatMap(dep -> client.sql(query)
.bind("departmentId", dep.getId())
.bindNull("managerId", Long.class)
.bind("managerId", dep.getManager().orElseGet(() -> Employee.builder().id(0L).build()).getId())
.fetch().rowsUpdated())
.thenReturn(department);
}We then need to persist the new relationship. A helpful feature of Mono, is that it returns 0 to 1 objects, so if the 'manager' is empty, .flatMap is not called and we skip to returning the Department at the end of the method.
private Mono<Department> saveDepartmentManager(Department department) {
String query = "INSERT INTO department_managers(department_id, employee_id) VALUES (:id, :empId)";
return Mono.justOrEmpty(department.getManager())
.flatMap(manager -> client.sql(query)
.bind("id", department.getId())
.bind("empId", manager.getId())
.fetch().rowsUpdated())
.thenReturn(department);
}To recap, we persist our Department, persist any nested entities (Employee), then create a relationship between the two.
Conclussion
As demonstrated above, building our own ORM-like system, isn't that difficult. We can overcome some of the limitations of Spring Data R2DBC that put so many people off.
That being said, not every project needs to be 'reactive'. Working with Flux and Mono can add a lot of complexity to a system. Non-blocking services are fantastic if resource efficiency and massive numbers of concurrent connections are your concern. If not, traditional blocking services are still very much viable.
This was a small look at reactive Spring Boot. In the future, I will have a full series on a reactive service using Spring Webflux and Spring Boot. If you do not want to wait, you can see the whole project on Github.
Happy Coding!